读《深入分析Java Web技术内幕》记录
随着Web 2.0时代的到来,互联网的网络架构已经从传统的
C/S架构转变为更加方便、快捷的B/S架构,B/S 架构大大简化了用户使用网络应用的难度,提高了用户体验。
B/S 架构带来了以下两方面的好处:
- 客户端使用统一的浏览器(
Browser)。由于浏览器具有统一性,不需要特殊的配置和网络连接。另外浏览器的交互特性使得用户使用它非常简便,且用户行为的可继承性非常强,也就是用户只要学会了上网,不管使用哪个应用,一旦学会了,便具备了使用其它任何互联网服务的经验。 - 服务端(
Server)基于统一的HTTP。和传统的 C/S 架构使用自定义的应用层协议不同。使用统一的 HTTP 简化了开发模式,并且基于 HTTP 的服务器又很多,如Apache、Nginx、Tomcat等,这些服务器可以直接拿来使用,不仅如此,连开发服务的通用框架也可以直接拿来使用,不需要单独开发,如Spring、Spring MVC、MyBatis等,我们只需关注服务的业务逻辑,同样简化了我们的开发工作。
B/S网络架构概述
B/S 基于统一的应用层协议 HTTP 来交互数据,与大多数 C/S 互联网应用程序采用的长连接的交互模式不同。HTTP 采用无状态的短连接的通信方式,通常情况下,一次请求就完成了一次数据交互,然后这次通信连接就断开了。采用这种方式可以有效应对更多的用户请求。
.jpg)
如图所示:当用户在浏览器输入网址回发生如下操作:
- 用户发起请求
- DNS把域名解析为对应IP
- 根据IP找到对应的服务器发起一个get请求,有这个服务器决定返回默认的数据资源给访问的用户。
- 服务器经过负载均衡等处理把数据返回给用户
- 如果浏览器解析数据时发现有静态资源,会发起另外的HTTP请求,这些请求可能会在CDN服务器上
如何发起一个请求
这个问题简单又复杂,简单是指当我们在浏览器里数据一个 URL 时,按下回车键就发起了这个 HTTP 请求,很快就可以看到这个请求的返回结果。复杂是指不借助浏览器也能发起请求。
Java可借助工具包发起请求,Linux下可以使用curl+url就可以简单发起HTTP请求。查看http头信息,加上-I选项
HTTP解析
要理解 HTTP,最重要的是要熟悉 HTTP 中的 HTTP Header,它控制着数据的传输。最重要的是,它控制着浏览器的渲染行为和服务器的执行逻辑。例如,当服务器没有用户请求的数据时就会返回一个 404 状态码,告诉浏览器没有要请求的数据,通常浏览器会展示一个非常不愿意看到的个 “该页面不存在” 的错误信息。
常见的 HTTP 请求头
| 请求头 | 说明 |
|---|---|
| Accept-Charset | 指定客户端接收的字符集 |
| Accept-Encoding | 指定可接受的编码(如 Accept-Encoding : gzip.deflate) |
| Accept-Language | 指定一种自然语言(如 Accept-Language : zh-cn) |
| Host | 指定被请求资源的主机和端口号(如 Host : www.baidu.com) |
| User-Agent | 客户端将它的操作系统、浏览器和其它属性告诉服务端 |
| Connection | 指定当前连接是否保持(如 Connection : Keep-Alive) |
常见的 HTTP 响应头
| 响应头 | 说明 |
|---|---|
| Server | 服务器名称(如 Server : nginx/1.17.6) |
| Content-Type | 发送给接收者的实体的类型(如 Content-Type : text/html;charset=GBK) |
| Content-Encoding | 与 Accept-Encoding 对应,服务端采用的编码 |
| Content-Language | 与 Accept-Language 对应,资源所用的自然语言 |
| Content-Length | 正文的长度 |
| Keep-Alive | 保持连接的时间(如 Keep-Alive : timeout=5) |
常见的 HTTP 响应头
| 状态码 | 说明 |
|---|---|
| 200 | 请求成功 |
| 302 | 临时跳转 |
| 400 | 客户端请求有语法错误,不能被服务器识别 |
| 403 | 服务器收到请求,但是拒绝提供服务,即没有权限 |
| 404 | 请求的资源不存在 |
| 500 | 服务器发生不可预期的错误 |
查看HTTP信息工具
要看一个 HTTP 请求的请求头和响应头可以通过 F12 快捷键打开浏览器的调试工具查看,例如我们正在访问 www.baidu.com,按下 F12 并打开 Network 调试栏可以看到以下 HTTP Header 内容
浏览器缓存机制
当浏览一个网页发现有异常时,通常要考虑的就是是不是浏览器做了缓存,所以一般的做法就是按 Ctrl + F5 组合键重新请求一次这个页面,这样的话请求的肯定是最新的页面。因为按 Ctrl + F5 组合键会直接向目标 URL 发送请求,而不会使用浏览器缓存的数据。
按 Ctrl + F5 组合键刷新页面后,会发现在 HTTP 的请求头中通常多了两个参数,分别是 Cache-Control:no-cache 和 Pragma:no-cache,该参数作用就是请求内容不会被缓存
| 参数 | Cache-Control/Pragma | Expires | Last-Modified/Etag |
|---|---|---|---|
| 值 | Public:所有内容都被缓存,在响应头设置。 Private:内容只缓存到私有缓存中,在响应头设置。 No-cache: 所有内容不会被缓存 No-store:所有内容不会被缓存到缓存或Intent临时文件中 Must-revalidation/proxy-revalidation:如果缓存内容失败,请求必须发送到服务器进行重新验证 Max-age=xx:缓存内容在xxx秒后失效,这个只在HTTP1.1可用。 |
通常使用格式是:Expries:Sat,25 Feb 2012 12:22:17 GMT 后面跟着一个日期和时间 | Last-Modified:时间 Etag:编号 |
| 含义 | 用于指定所有缓存机制在整个请求响应链中必须服从的指令。 | 超过这个时间值,缓存的内容将失效。也就是浏览器在发出请求之前检查这个页面这个字段,看该页面是否已经过期了,过期了就重新向服务器发起请求。 | Last-Modified字段一般用于一个服务器上的资源最后修改时间,资源可以是静态(静态内容自动加上Last-Modified)或者动态的内容(Servlet提供一个getLastModified方法用于检查某个动态内容是否已经更新),通过这个最后修改时间可以判断当前请求的资源是否最新的。 Etag这个字段让服务器给每个一个页面分配一个唯一编号,区分当前这个页面是否最新的。 |
DNS域名解析
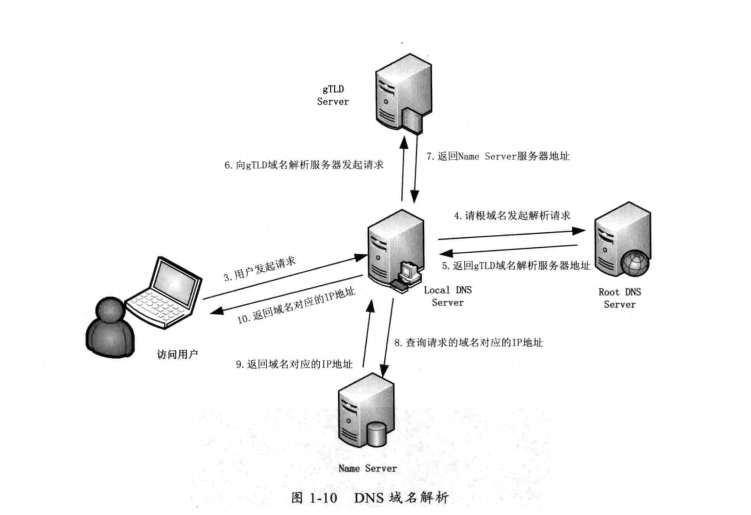
如上图所示,当用户在浏览器输入地址是,DNS解析将会有将近10个步骤:
浏览器会检查缓存中有没有这个域名对应的解析过的IP地址,如果缓存有,这个解析就将结束。
如果用户的浏览器中没有,浏览器会查找操作系统缓存中是否有这个域名对应的DNS解析结果。即查找本机系统中的hosts文件,如查找到,解析也将结束
怎么知道域名服务器呢?在我们的网络配置中有DNS服务器的地址,也就是LDNS(本地域名服务器)
80%的域名解析在第三步的时候就完成了,如果LDNS仍然没有命中,就直接到Root Server域名服务器请求解析。
根域名服务器返回给LDNS一个所查询域的主域名服务器(gTLD Server,国际顶尖域名服务器,如.com .cn .org等,全球只有13台左右)地址
此时LDNS再发送请求给上一步返回的gTLD
接受请求的gTLD查找并返回这个域名对应的Name Server的地址,这个Name Server就是网站注册的域名服务器
Name Server根据映射关系表找到目标ip,返回给LDNS
LDNS缓存这个域名和对应的ip
LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
CDN工作机制
CDN内容分布网络(ContentDelivery Network)是构筑在现有的Internet上的一种先进的流量分配网络。其目的是在现有的Internet上增加一层新的网络架构,将网站的内容发布到最接近用户的服务器,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。 一个CND架构=镜像(Mirror)+ 缓存(Cache)+整体负载均衡(GSLB)。
技术原理:在 CDN 的 DNS 解析中通过动态的链路探测来寻找回源最好的一条路径,然后通过 DNS 的调度将所有请求调度到选定的这条路径上回源,从而加速用户访问的效率。